DeeperLab: Single-Shot Image Parser
-
Tien-Ju Yang
MIT -
Maxwell D. Collins
Google -
Yukun Zhu
UC Berkeley -
Jyh-Jing Hwang
UC Berkeley -
Ting Liu
Google -
Xiao Zhang
Google -
Vivienne Sze
MIT -
George Papandreou
Google -
Liang-Chieh Chen
Google
Abstract
We present a single-shot, bottom-up approach for whole image parsing. Whole image parsing, also known as Panoptic Segmentation, generalizes the tasks of semantic segmentation for 'stuff' classes and instance segmentation for 'thing' classes, assigning both semantic and instance labels to every pixel in an image. Recent approaches to whole image parsing typically employ separate standalone modules for the constituent semantic and instance segmentation tasks and require multiple passes of inference. Instead, the proposed DeeperLab image parser performs whole image parsing with a significantly simpler, fully convolutional approach that jointly addresses the semantic and instance segmentation tasks in a single-shot manner, resulting in a streamlined system that better lends itself to fast processing. For quantitative evaluation, we use both the instance-based Panoptic Quality (PQ) metric and the proposed region-based Parsing Covering (PC) metric, which better captures the image parsing quality on 'stuff' classes and larger object instances. We report experimental results on the challenging Mapillary Vistas dataset, in which our single model achieves 31.95% (val) / 31.6% PQ (test) and 55.26% PC (val) with 3 frames per second (fps) on GPU or near real-time speed (22.6 fps on GPU) with reduced accuracy.
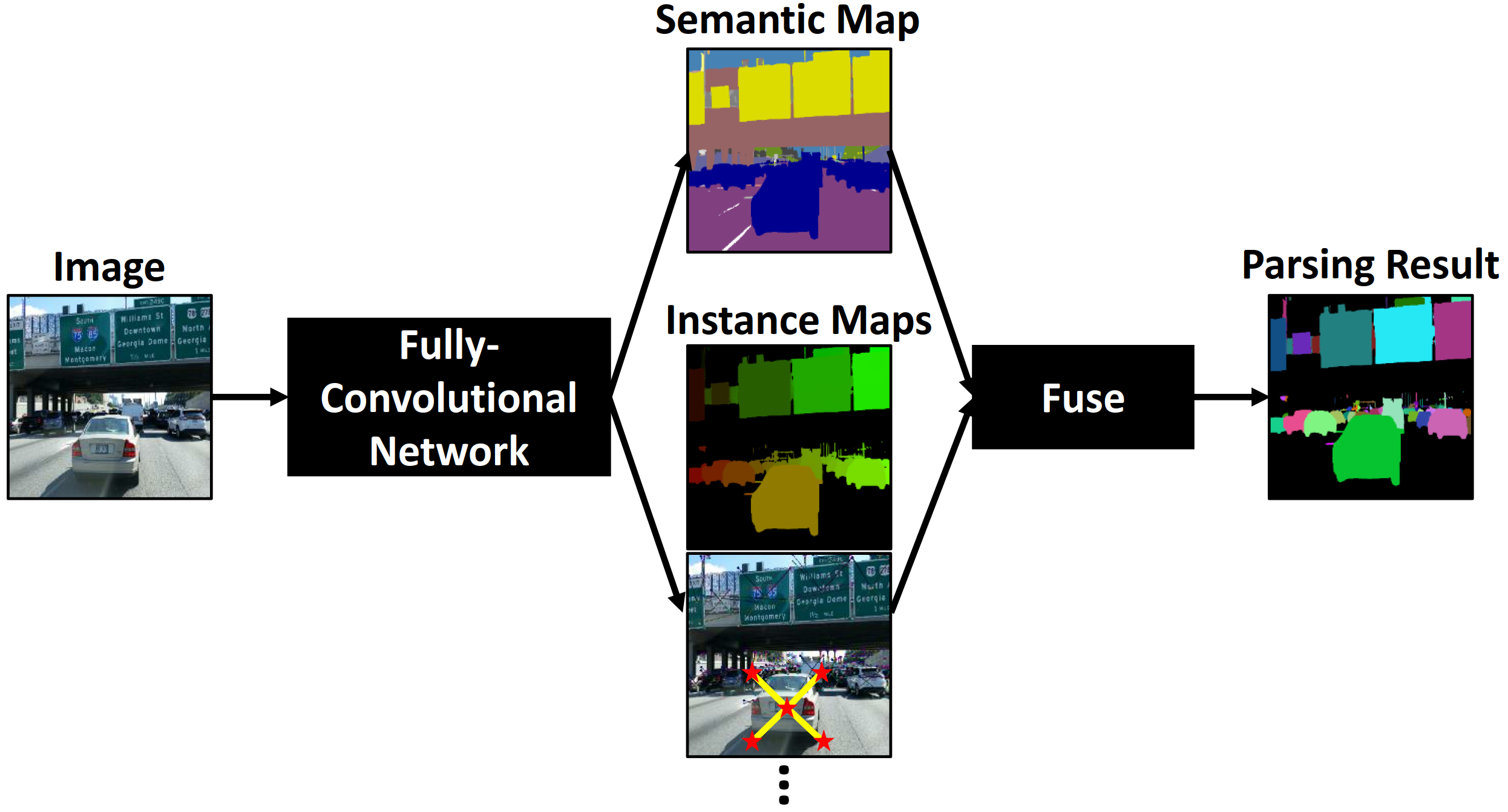

Illustration of DeeperLab
Performance on Mapillary Vistas Validation Set

Visualization on Mapillary Vistas Validation Set
Downloads
BibTeX
@article{arxiv_2019_yang_deeperlab,
title={{DeeperLab: Single-Shot Image Parser}},
author={{Yang, Tien-Ju and Collins, Maxwell D. and Zhu, Yukun and Hwang, Jyh-Jing and Liu, Ting and Zhang, Xiao and Sze, Vivienne and Papandreou, George and Chen, Liang-Chieh}},
journal={{arXiv preprint arXiv:1902.05093}},
year={{2019}}
}